Affective/Empathic Responses
- Enabling Emotional Intelligence with VR and Physiological Sensing (2024 +)
- Guiding vs. Restoring Attention in Virtual Environments (2019 – 2023)
- Enhancing Collaborative Communication and Dataset Exploration in VR (2019-2024)
- Affective Tasks for Eliciting Emotion in VR (2017+)
- Reporting Emotional Reactions in Real Time
- Empathy Assessment and Emotion Reporting (2023+)
- Deep User Identification in Sensor-Rich VR Environments
- Recognizing Emotions from Physiological Responses
- Detecting Distraction From Eye And Head Movement (2022)
- Pedagogical Agents (2018+)
Enabling Emotional Intelligence with VR and Physiological Sensing (2024 +)
Researchers: Niloofar Heidarikohol
Description:
Stress can be described as a condition of worry and mental pressure experienced by humans when faced with harsh circumstances. According to a Gallup poll, 66% of students suffer from stress, and 51% suffer from worry. Stress can significantly impact individuals’ cognitive, behavioral, emotional, and physical aspects, leading to a notable decline in productivity and efficiency in daily tasks such as academic performance.
Some functional techniques, including retaining physiological responses such as breathing and body response awareness, can play crucial roles during the peak of negative emotions. This project explores methods to enhance emotional intelligence through a VR environment equipped with biofeedback and physiological sensors, including heart rate, skin conductivity, and pupil size and movement.
The long-term goal is to enhance young people’s emotion self-regulation and emotional resilience skills based on the insights gained from our initial designs and experiments. Moreover, we designed an effective VR nature-based environment for developing Emotional Intelligence (EI) and awareness of the physiological state. We incorporated biofeedback from various sensors to collect heart rate data and convert it into real-time heart rate feedback. We collected users’ data from experiments to optimize the designed environment and heart rate biofeedback modalities.
The first phase of the project involved providing two survey papers. The primary focus of the survey is to identify the VR setting that emphasizes emotional intelligence types. We evaluated 40 papers out of 822 papers for one paper using the PRISMA method and published a survey paper in IEEE VRW 2025.
The University of Louisiana at Lafayette funded the project for two consecutive years, starting in August 2024.

Caption: The Heart Rate Feedback (HRF) nature scene. Subjects experience various heart rate feedback modalities, including visual, auditory, and haptic, in the environment.

Caption: The subject wears an HTC Vive headset, a Haptic vest, and a Polar watch during the experiment.
Publications:
N. Heidarikohol and C. W. Borst, “A Survey of Emotional Intelligence Applications in Immersive and Non-Immersive Technologies” 2025 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW), Saint Malo, France. 2025, pp. 997-1004, doi: 10.1109/VRW66409.2025.00202. (PDF)
U. A. Jinan, N. Heidarikohol, C. W. Borst, M. Billinghurst, S. Jung, “A systematic review of using immersive technologies for empathic computing from 2000-2024.” Empathic Computing 1.1 (2025): 202501-202501. (PDF)
Guiding vs. Restoring Attention in Virtual Environments (2019 – 2023)
Researchers: Andrew Yoshimura, Nicholas Lipari, and Jason Woodworth
Description:
Distraction in VR training environments may be mitigated with a visual cue intended to guide user attention to a target. A survey of related literature suggests a past focus on “search and selection” tasks to evaluate a cue’s capability for guidance to unknown targets, but they do not study the effect of guiding a user’s attention to a known target after it is lost. To address this, we are investigating visual attention cues in VR with a focus on how to restore attention attention when a short distraction (e.g., a notification) shifts focus away from a target.
We performed a study comparing 9 eye-tracked cues with a new type of task different from the standard “search and selection.” We initially conducted a tuning study to find ideal parameters for each cue, including settings like cue shape and visual fade with gaze angle from target. Our main study then included a guidance task, in which subjects gazed at new targets in a randomized order, and a restoration task, in which gaze sequences were interrupted by distraction events after which gaze must be returned to the target object. We considered a wider variety of factors and metrics than previous studies, varying object spacing, gaze dwell time, and distraction distance and duration, resulting in a 10x3x2x2 within-subjects experiment design.
Results show a general positive trend for cues that directly connect the user’s gaze to the target rather than indirectly suggesting direction. Results further reveal different patterns of cue effectiveness for the restoration task than for conventional guidance. This may be attributed to knowledge that subjects have about the location of the object from which they were distracted. An implication for more complex dis traction tasks is that we expect them to be between the short distraction and regular guidance in terms of memory of object position. So, we speculate cue performance for other tasks would vary between the short distraction and guidance results. For restoration, some cues add complexity that reduces, rather than improves, performance. Future studies may further investigate this difference.

The 9 visual cues compared in our study.
Videos:
Related Publications:
J. W. Woodworth and C. W. Borst, “Visual cues in VR for guiding attention vs. restoring attention after a short distraction,” Computers & Graphics (118), pp. 194-209, 2024, doi: 10.1016/j.cag.2023.12.008.
J. W. Woodworth, A. Yoshimura, N. G. Lipari and C. W. Borst, “Design and Evaluation of Visual Cues for Restoring and Guiding Visual Attention in Eye-Tracked VR,” 2023 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW), Shanghai, China, 2023, pp. 442-450, doi: 10.1109/VRW58643.2023.00096.
Enhancing Collaborative Communication and Dataset Exploration in VR (2019-2024)
Researchers: Adil Khokhar, Md Istiak Jaman Ami, Niloofar Heidarikohol
Description:
Effective collaboration in VR hinges not only on shared visuals but on the rich tapestry of nonverbal cues that ground human understanding. In affective computing gaze communication, eye gaze is a fundamental social signal—revealing attention, intent, and even emotional state—that tutors and learners use to align their mental models.
In a collaborative VR environment displaying high‑resolution terrain of the Yucatán Peninsula and Lake Constance, we evaluate how real‑time gaze visualization overlaid on the user’s video feed enhances spatial guidance and annotation tasks. Tutors see a live cursor representing the student’s eye–head gaze point, allowing immediate identification of referents without extra verbal clarification. We studied how visual indicators of a person’s gaze affects communication with someone guiding them through tasks in which they search for 3D surface features.
For example: Imagine you’re the tutor in a remote, one‑on‑one VR session. Your student looks at a 3D terrain dataset and asks, “What’s the name of this ridge?” but you can’t see their gaze or guess from their gestures to know which ridge they mean. Without these non‑verbal cues—like gaze direction—you find yourself asking them to describe it more to narrow it down, breaking the flow of the lesson and leaving both of you frustrated.
We did a study investigating the effects of gaze visualization on tutoring effectiveness by exploring spatial guidance strategies used in a collaborative geosciences virtual reality (VR) environment and examines effects on three different types of spatial guidance tasks involving the identification, alignment, and analysis of terrain features across different terrain datasets, while being able to display them all at once in various ways like overlays and tiles. We use these features to support our user study where we investigate gaze visualization’s effects on guidance. A confederate student is used to control for mistakes and how and when to elicit guidance from the tutor.
Overall, the integration of gaze visualization into VR educational settings appears to significantly improve the efficiency and effectiveness of spatial guidance, improving guidance in educational tasks that demand precise spatial orientation and interaction.

Left: Tutor correcting student misunderstanding when circling a feature near target region. Middle: Student considering which tile matches the highlighted region. Right: Tutor directing student by describing matching terrain features in tiles.

The experimental setup with the tutor and confederate student. Note that the TV is not part of the experiment itself, but was just used to show what the tutor’s view is like in the headset.
Videos:
Publications:
Khokhar, A., Borst, C. W., Ami, M. I. J., & Heidarikohol, N. (2025). Enhancing Collaborative Dataset Exploration in VR: The Impact of Gaze Visualization on Tutors’ Spatial Guidance and Communication. 596–603. https://doi.org/10.1109/VRW66409.2025.00125
Borst, C. W., Lipari, N. G., & Woodworth, J. W. (2018). Teacher-Guided Educational VR: Assessment of Live and Prerecorded Teachers Guiding Virtual Field Trips. 2018 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), 467–474. https://doi.org/10.1109/VR.2018.8448286
Woodworth, J. W., Broussard, D., & Borst, C. W. (2019). Collaborative Interaction in Large Explorative Environments. Symposium on Spatial User Interaction, 1–2. https://doi.org/10.1145/3357251.3360017
Affective Tasks for Eliciting Emotion in VR (2017+)
Researchers: Jason Woodworth
Achieving automated emotion recognition requires large datasets of users’ physiological and behavioral responses to emotional stimuli. To help capture such datasets, researchers have created libraries of stimuli ranging from images to videos to virtual environments. However, many of these libraries contain only passive stimuli that don’t require the user to actively interact with them. Those that contain video often use narratives that expect a user to empathize with characters in ways that may not be culturally ubiquitous. The emotions they target also tend to not relate to those associated with the training or educational tasks common in VR, such as frustration or boredom.
The capability of VR to enhance engagement through its immersive interactivity is a core selling point of the medium, and so we sought to create a library of active affective stimuli that would use VR to quickly elicit emotions from the user without need for narrative devices. Our initial library includes 4 affective tasks (and alternate neutral variants) that aim to elicit frustration, confusion, excitement, and boredom. Our study showed general success in eliciting a broad range of emotions on par with those in a passive video library. Future work looks to extend this set of tasks with others and make them more universally usable.
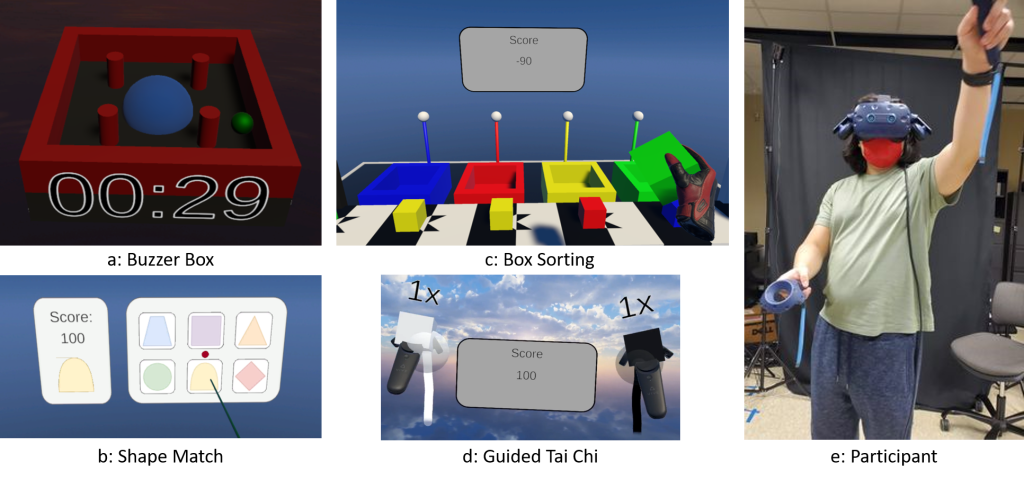
Affective Tasks. a: Buzzer Box asks the user to keep the green ball in the blue dome center while an invisible force pushes it away. b: Shape Match asks the user to select the shape shown on the left from the selection on the right. c: Box Sorting asks the user to sort the box into the correctly colored bin while occasionally giving incorrect feedback for correct sorts. d: Guided Tai-Chi asks the user to follow the colored spheres with their tracked hands while providing positive feedback. e: A participant performing Tai-Chi.
Videos:
Presentation of early work describing each task.
Video description of the experiment presented at IEEE 2024
Related Publications:
J. W. Woodworth and C. W. Borst, “Design and Validation of a Library of Active Affective Tasks for Emotion Elicitation in VR,” 2024 IEEE Conference Virtual Reality and 3D User Interfaces (VR), Orlando, FL, USA, 2024, pp. 398-407, doi: 10.1109/VR58804.2024.00061. (PDF)
J. W. Woodworth and C. W. Borst, “Designing immersive affective tasks for emotion elicitation in virtual reality,” 2nd Momentary Emotion Elicitation and Capture Workshop, 2021(PDF)
User Interfaces for Reporting Emotional Reactions in Real Time
Researcher: Jason Woodworth
Our research is improving the way users can tell a computer how they’re feeling. Such self-reported emotional responses are critical for developing emotion recognition systems that will allow computers to adapt to their users on the fly. Emotional responses can naturally vary throughout a stimulus, such as 360-degree video or other VR experiences, but most interfaces for reporting emotion are designed to be used after the experience. This reduces the entire experience to a single data point and raises concerns about validity when multiple emotions can be elicited across the stimulus.
In this project, we introduced and compared user interfaces that allow for real-time emotion reporting throughout the length of the stimulus. Each interface varies on how emotion is physically input by the user and displayed back to them for confirmation. A preliminary study compared five such interfaces, gathering initial impressions, comparing control schemes, and rating intuitiveness. A primary study considered four refined interface designs and compared reporting precision and subjective opinions. Results suggest that a single interface face icon responding to arousal and valence reports and a gradiating color wheel are intuitive, precise, and unobtrusive. More broadly, results indicate the type of rating interface has a significant effect on the given ratings.

The interfaces compared across our studies with example 360° videos. Visuals show either a happy or sad report. Images are cropped/zoomed to increase interface detail due to the large field of view in VR.
Video:
Related Publications:
J. W. Woodworth and C. W. Borst, “Study of Interfaces for Time-Continuous Emotion Reporting and the Relationship Between Interface and Reported Emotion,” 2024 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Bellevue, WA, USA, 2024, pp. 884-892, doi: 10.1109/ISMAR62088.2024.00104. (PDF)
J. W. Woodworth and C. W. Borst. “Design of Time-Continuous Emotion Rating Interfaces,” Proceedings of the 29th ACM Symposium on Virtual Reality Software and Technology (VRST ’23). 2023. (PDF)
Empathy Assessment and Emotion Reporting in VR (2023+)
Researchers: Md Istiak Ami , Jason Woodworth
Emotional experiences like empathic concern (EC) and personal distress (PD) often unfold over time and can be influenced by a range of emotionally charged situations. To study these dynamic processes, we use immersive virtual reality environments that simulate emotion inducing scenarios, such as an infant crying VR180 video, and allow participants to report their emotions continuously.
A central challenge in emotion research is designing rating interfaces that allow participants to continuously and accurately report multiple emotional states, without interfering with the immersive experience. Ideal interfaces should be minimally invasive, cognitively lightweight, intuitive to operate, and capable of supporting multi-dimensional input. Earlier work in our lab focused on designing time-continuous emotion rating interfaces for reporting valence and arousal levels [Woodworth & Borst, VRST 2023]. In this project, we address those above-mentioned challenges but focus on empathic responses, developing and testing systems that allow real-time, parallel reporting of EC and PD using custom input devices. These interfaces are evaluated for usability and consistency to ensure they support natural interaction without overwhelming the user.
To complement self-reported ratings, we also collect physiological responses (e.g., EEG, heart rate, electrodermal activity, and so on) and eye responses. This multimodal approach allows us to evaluate both emotional dynamics and the usability of time-continuous, multi-dimensional input systems. A key focus is understanding whether users can process and report multiple emotional states simultaneously, and identifying factors that may hinder this, such as attention shifts, cognitive load, or interface design.

A User Watching a VR180 Infant Crying Video through a VR headset, and Providing Time-continuous Response of Personal Distress and Empathic Concern Level using the Continuous Rating Interfaces.
The broader goal is to inform the design of emotionally aware systems and support applications in caregiver training, mental health support, and affect-sensitive human-computer interaction. Future work includes extending the interfaces to additional emotional dimensions (e.g., dominance, valence, arousal, fidelity, and so on), and building emotion recognition models from
combined physiological and behavioral data.
Research Fields:
-
Human-Computer Interaction (HCI)
-
User Interface and Interaction Design
-
Virtual Reality (VR)
-
Affecting Computing
-
Emotion and Empathy Research
Related Article:
Ami, M. I. J., Woodworth, J. W., & Borst, C. W. (2024, March). Design of Time-Continuous Rating Interfaces for Collecting Empathic Responses in VR, and Initial Evaluation with VR180 Video Viewing. In 2024 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW) (pp. 1041-1042). IEEE. (PDF)
Jason Wolfgang Woodworth and Christoph W Borst. 2023. Design of Time-Continuous Emotion Rating Interfaces. In Proceedings of the 29th ACM Symposium on Virtual Reality Software and Technology (VRST ’23). Association for Computing Machinery, New York, NY, USA, Article 48, 1–2. (PDF)
Deep User Identification in Sensor-Rich VR Environments (2022 – 2024)
Researchers: Bhoj Karki
This project explores how behavioral and physiological signals collected in Virtual Reality (VR) environments can be used to identify users through biometric patterns. As VR becomes more widely adopted in education, training, and simulation, it enables the collection of rich sensor data, such as movement, gaze, and emotional responses, that reflect how individuals interact in immersive spaces. These capabilities open new possibilities for personalization and adaptive system design, while also raising important considerations about biometric uniqueness, permanence, and the implications of passive data collection.
Leveraging deep learning algorithms, this work investigates how multimodal sensor fusion can support reliable and accurate user identification across varied interaction contexts. The findings from this project offer valuable insights into the behavioral and physiological characteristics that contribute to biometric distinction in VR, and highlight key factors that should be considered when designing future systems that are both adaptive and mindful of privacy.
Research Opportunities:
Students and collaborators may contribute to this project by exploring interaction-aware deep learning models, designing diverse VR task sets for robust biometric modeling, identifying privacy-sensitive data traits, or developing adaptive user interfaces informed by behavioral biometrics in immersive environments.
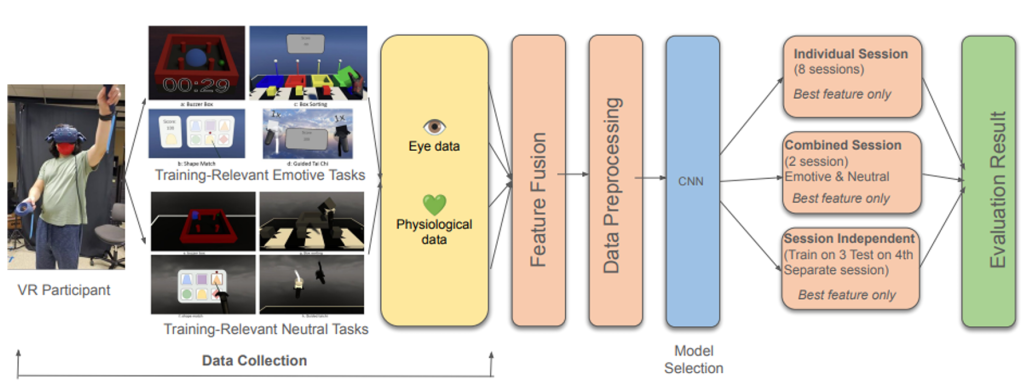
System design illustrating emotion eliciting and neutral tasks, multimodal data preprocessing, and cross-session analysis for user identification.
Recognizing Emotions from Physiological Responses (2022-2024)
Researchers: Bharat KC
This project explores emotionally intelligent system design by incorporating multimodal sensing – physiological (electroencephalography, electrodermal activity, and heart rate) and eye tracking data, with immersive virtual reality experiences. Aiming to elicit a wide range of emotional states in subjects, we designed a unique data collection setup using both passive (360° video) and active (interactive VR tasks) stimuli. At its core, the research introduced a novel multimodal dataset and transformer-based architectures, evaluating with different modalities and stimuli for emotion recognition. The models demonstrated high accuracy in detecting multiple emotion categories, highlighting the effectiveness of our approach.
The broader goal of this work lies in advancing the development of the emotionally aware system, which has the potential to transform how machines interact with people, enabling empathetic and personalized experiences. Applications of this research span context-sensitive VR environments, mental health monitoring, adaptive education, immersive entertainment, and human-robot interaction. Our project contributes a meaningful step toward the future of emotionally responsive technologies.
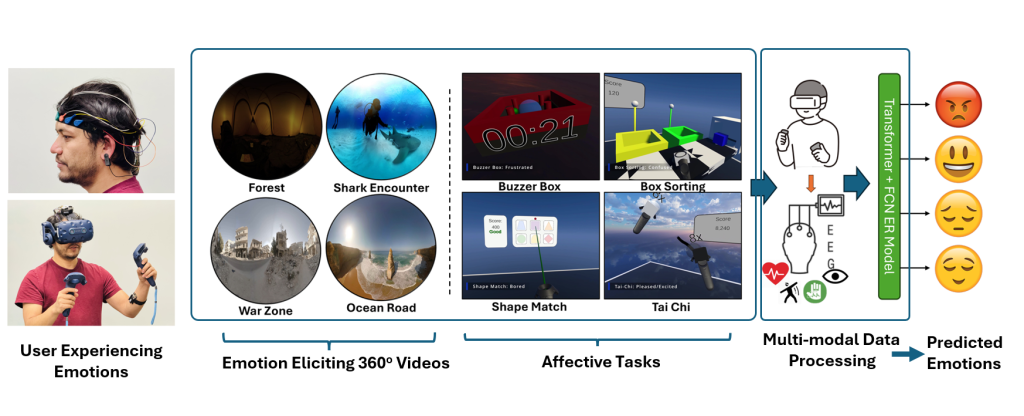
An overview of building emotion recognition models. Users are exposed to emotional stimuli (left: passive, right: active) and their physiological reactions are recorded and used to train machine learning based models.
Related article:
Bharat, K. C., Karki, B., Khokhar, A., Woodworth, J. W., & Borst, C. W. (2025, March). Emotion Recognition in Interactive VR Tasks and in 360VR Videos with Transformer-Based Approach and Multimodal Sensing. In 2025 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW) (pp. 299-306). IEEE.(PDF)
Detecting Distraction From Eye And Head Movement (2022)
Researchers: Adil Khokhar
We have shown how AI can be used to detect a trainee’s attention or distraction to help the system give personalized feedback. We tested our approach in an introduction of a virtual oil rig.
Distractions can interrupt critical learning moments during educational virtual reality experiences. We created a dataset of generalized metrics someone’s motion (controllers, head, and eye) in a VR headset. By learning motion patterns, the system can tell when a user’s attention drifts during an educational field trip to a virtual oil rig.
Built on generalized motion signals (like how fast you turn your head or blink), we evaluated our dataset by training a CNN-LSTM classifier that successfully spotted moments of distraction with over 94 % accuracy.
This means future VR lessons could:
-
Gently pause and offer a hint when you look away
-
Adapt the pace or difficulty to keep you engaged
-
Personalize feedback based on your focus patterns
Beyond classrooms, this kind of attention detector could power adaptive training for industry, help design more engaging games, or even monitor focus during remote meetings. By giving VR educational experiences the ability to sense when you’re truly “in the moment,” we can make learning and engagement more responsive and effective.

Left: A student looks at the correct object the teacher is pointing at (a gaze trail is shown here but is not visible to the student). Right: The teacher points and a student’s gaze drifts towards the wrong object due to a distraction prompt on their in-game mobile device
Video:
Publications:
Khokhar, A., & Borst, C. W. (2022). Towards Improving Educational Virtual Reality by Classifying Distraction using Deep Learning. The Eurographics Association. (PDF)
Pedagogical Agents (2018+)
Researchers: Adil Khokhar
We designed an automated instructor character that is responsive to students’ eye gaze and adapts its guidance in real time during VR oil rig training. For example, if an instructor points out a critical oil-rig valve and the student’s gaze drifts from the valve to the background scaffolding, the agent will pause and interactively guide the student’s focus back on the valve.
At its core is an annotation-driven sequencing system which sequences prerecorded instructor clips—captured via Kinect V2 —based on real-time eye tracking of student gaze. By defining generalized hotspots, responsive guidance can be delivered. The avatar can respond dynamically when a learner’s attention drifts, creating a seamless interactive experience. [Collapse or combine these two sentences].
Generalized hotspots allow detection and you have some AI architecture for the sequencer to respond (some approach or some architecture that allow the sequencer to respond to these hotspots). (Want to make it clear that it’s more than just the kind of hotspot where someone looks at a thing and it triggers something).
In a virtual oil-rig field trip study, we compared three agent behaviors—Continue, Pause, and Respond—to see which level of interactivity learners found most suitable. Results showed that highly interactive “Respond” behaviors significantly improved perceptions of naturalness, appropriateness, and engagement over static or minimal interventions. These findings inform design guidelines for next-generation educational VR agents, demonstrating that timely, gaze-aware feedback can enhance learning engagement and reduce confusion in immersive training scenarios.

Left: A student looks where the teacher agent points at after the teacher agent responds to their gaze drifting by asking them to look a little higher (a gaze trail is shown near the center of this image but is not visible to the student). Right: Teacher agent pauses and waits when pointing to blue barrels if student looks away.
Videos:
Publications:
Khokhar, A., & Borst, C. W. (2022). Towards Improving Educational Virtual Reality by Classifying Distraction using Deep Learning. The Eurographics Association. https://doi.org/10.2312/egve.20221279
Khokhar, A., & Borst, C. W. (2022). Modifying Pedagogical Agent Spatial Guidance Sequences to Respond to Eye-Tracked Student Gaze in VR. Symposium on Spatial User Interaction, 12. https://doi.org/10.1145/3565970.3567697
Khokhar, A., Yoshimura, A., & Borst, C. W. (2020). Modified Playback of Avatar Clip Sequences Based on Student Attention in Educational VR. 2020 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW), 850–851. https://doi.org/10.1109/VRW50115.2020.00276
Khokhar, A., Yoshimura, A., & Borst, C. W. (2019). Pedagogical Agent Responsive to Eye Tracking in Educational VR. 2019 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), 1018–1019. https://doi.org/10.1109/VR.2019.8797896
- Christoph W. Borst, “Predictive Coding for Efficient Host-Device Communication in a Pneumatic Force-Feedback Display”, IEEE WorldHaptics 2005 conference, pp. 596-599. (link)